
Why flat files fail — the six problems that forced databases into existence
Every feature in every database you've ever used exists because someone, somewhere, watched their data get destroyed by one of six specific failure modes.

In 1969, an engineer at a company called North American Rockwell was trying to track parts inventory across an Apollo spacecraft manufacturing programme. The data lived in flat files — sequential binary files on magnetic tape, organised by hand, read and written by custom programs. The system worked, mostly, until two inventory clerks updated the same part count at the same time from different terminals. The writes interleaved. The count became nonsense. Nobody noticed for three days.
That’s not a story about incompetent engineers. It’s a story about the six failure modes that are unavoidable when you store structured data in plain files without a coordinating layer. Those failure modes are the reason databases were invented, and they’re the reason every ACID property exists. ACID isn’t a philosophy — it’s a checklist of the six things that go wrong.
This issue is about each failure mode in concrete detail. Read it slowly. For each one, hold the scenario in mind before reading the fix. The fix will make more sense once the problem has sat with you for a moment.
Before we start: what a flat file actually is
A flat file, in this context, is any file that stores structured data without a database managing it. A CSV of customer records. A binary file of account balances. A JSON file of product inventory. The file has structure — it’s not random bytes — but that structure is purely a convention enforced by the programs that read it. Nothing enforces the structure at the storage level. Nothing coordinates access between multiple programs. Nothing guarantees the file’s contents are consistent after a crash.
These are the conditions under which all six failure modes emerge.
Failure mode #1: concurrent write corruption

The animated diagram shows exactly how this happens. Process A and Process B are both updating the same account balance — Process A deducting $10, Process B deducting $20. Both read the current value (100) into their local memory. Process A writes back 90. Process B, holding its stale read of 100, writes back 80. Process A’s $10 deduction is gone. The balance is $80 when it should be $70.
This is the lost update anomaly, and it is the most common data corruption scenario in systems that use files without locking.
The underlying mechanism is simple. A file is a sequence of bytes. When two programs write to overlapping regions at the same time, the OS provides no ordering guarantee. Writes from different processes can interleave at any granularity — including mid-field, mid-record, or mid-integer. You don’t just get wrong values; you can get physically corrupted records where the bytes of one write appear inside the bytes of another.
The flat file workaround: Advisory file locks — flock() or fcntl() locks on Unix. One process locks the file, makes its changes, unlocks it. Serialised access prevents concurrent corruption. The problem is that advisory locks are advisory — nothing forces every program that touches the file to acquire the lock first. A rogue or buggy process can write to the file without the lock, and the lock provides zero protection. File locks are an honour system.
Why databases solve this properly: A database is the sole process that touches the underlying storage files. All access goes through the database engine, which enforces locking or MVCC (multi-version concurrency control) for every read and write. There is no way to write to a table without going through the engine’s concurrency control. The problem is architecturally impossible in a well-designed database, not just avoided by convention.
Failure mode #2: no atomicity
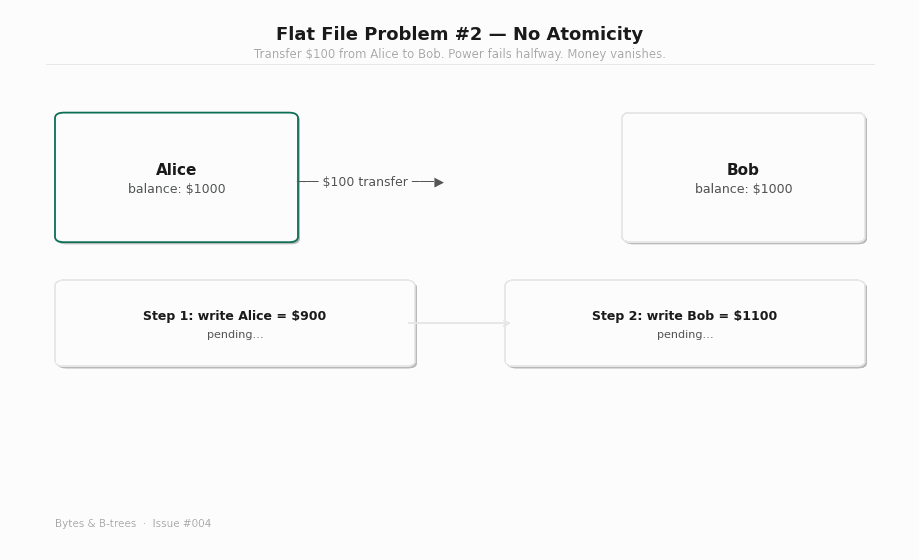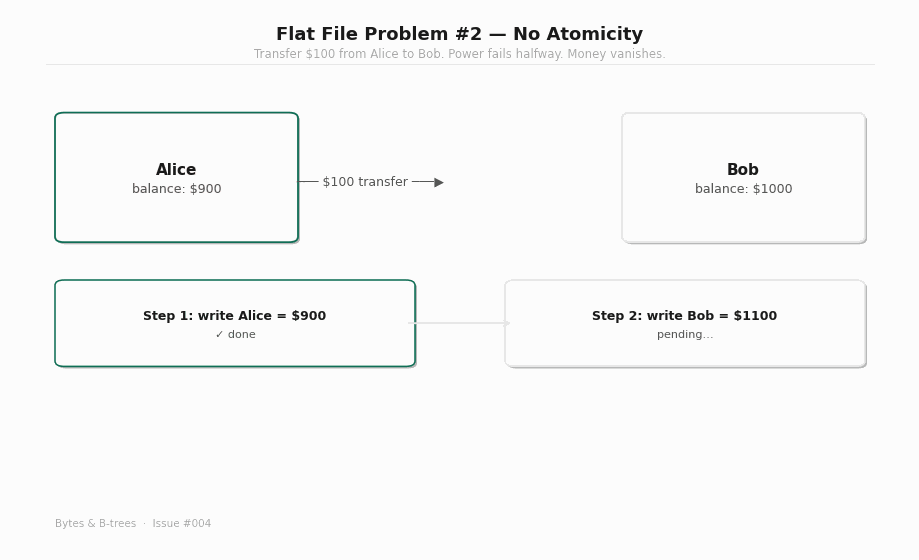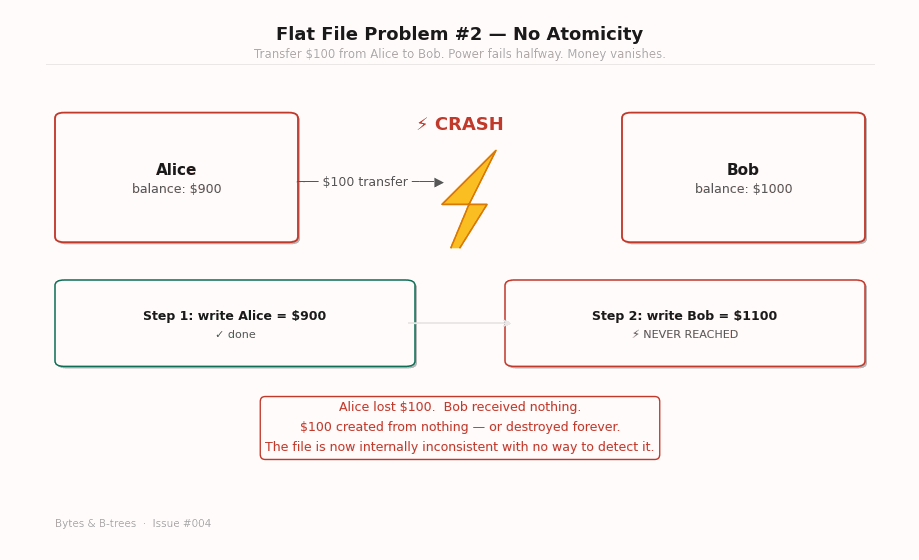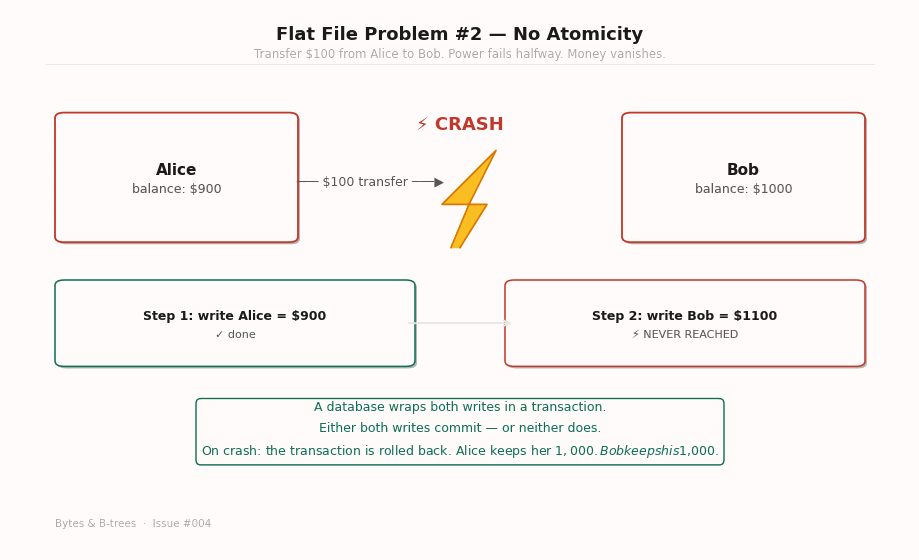
A bank transfer has two steps: debit the sender, credit the receiver. With flat files, these are two separate write() calls. If the system crashes between them — power failure, kernel panic, OOM kill — one write has completed and the other has not. The file on disk is internally inconsistent: the sender’s balance is already reduced, but the receiver’s balance was never increased. Money was destroyed.
This specific failure is what motivated the invention of database transactions. The insight is that some operations are only meaningful as a unit — either both succeed, or neither does. There’s no meaningful intermediate state where the debit has happened but the credit hasn’t. That state is not “partially completed” — it’s corrupted.
The formal name for this property is atomicity: an atomic operation either completes entirely or leaves no trace. The name comes from the Greek atomos — indivisible. A transaction is the indivisible unit of database work.
The flat file workaround: Write to a temporary file, then rename it to replace the original. A rename on a Unix filesystem is atomic at the OS level — either the old name or the new name exists, never neither, never both. This works for single-file replacements. It doesn’t work for operations that span multiple files (like two account balance files), because you can’t atomically rename two files simultaneously. And it doesn’t work for in-place updates within a single file at all.
Why databases solve this properly: The write-ahead log. Before modifying any data, the database writes a log record describing what will change. The log is flushed to disk with fsync(). Then, and only then, does the actual data change. If the machine crashes after the log write but before the data change, the database replays the log on recovery. If it crashes before the log write, the transaction never happened. Either way, the data files are always in a state that reflects only complete transactions.
We covered the WAL in issues #001 and #002. Now you know exactly why it exists: atomicity is impossible without it.
Failure mode #3: no crash recovery
Atomicity addresses the “half-written transaction” problem. Crash recovery is the broader problem: after a crash, how do you know which bytes in the file are valid?
With a flat file, you don’t. A crash mid-write leaves the file in an unknown state. The bytes written before the crash are there. The bytes that would have been written after are missing. But the file has no record of when the crash happened, which bytes are from the crashed write, or what the intended final state was. The file is just bytes. Some of them might be corrupted. You have no way to tell which ones.
This gets worse with buffered writes. Because the OS page cache holds dirty pages in memory before flushing them to disk, a crash might discard writes from minutes ago — not just the most recent operation. A program that wrote 1,000 records, each acknowledged as successful by write(), might find on recovery that only 850 of them actually made it to disk. The other 150 were in the page cache when the machine died.
The scale of this problem in practice: Imagine a long-running import job: loading 10 million customer records from a CSV into a binary file. After 8 hours, the job is 80% done and the server crashes. Without crash recovery, you have a partially written file. Do you start over? Do you try to figure out where the file is consistent and resume from there? Do you trust the 8 million records that are supposedly there? With a flat file, these questions have no good answers.
Why databases solve this properly: Databases track a recovery point — the last known consistent state — called a checkpoint. The WAL contains every operation after the last checkpoint. On recovery, the database replays the WAL from the checkpoint to reconstruct the full state. The data files are guaranteed to reflect complete transactions only. There’s no ambiguity about which bytes are valid — the WAL defines exactly what the correct state is.
We’ll spend all of issues #040 and #041 on the ARIES recovery algorithm, which is how nearly every production database implements crash recovery correctly.
Failure mode #4: no isolation
Isolation is the property that concurrent transactions don’t see each other’s intermediate states. With flat files, there’s no such guarantee.
Consider a read-heavy reporting query that needs a consistent view of all account balances — a snapshot in time. While it’s reading, other processes are updating balances. The query reads Alice’s balance at time T=0: $1,000. Then another process transfers $200 from Alice to Bob. The query reads Bob’s balance at time T=1: $1,200. The query now has an inconsistent snapshot — it sees the post-transfer Bob balance but the pre-transfer Alice balance. The sum of all balances is wrong.
This is the non-repeatable read anomaly. There are worse ones. A phantom read occurs when a query runs twice and finds different rows because another process inserted or deleted between the two reads. A dirty read occurs when a process reads data that another process has written but not yet committed — data that might be rolled back. All of these arise from the absence of isolation between concurrent readers and writers.
Why isolation is hard without a database: You’d need to freeze the file at the start of every read and unfreeze it after. With a large file and a long-running read, that means nobody else can write for the duration of the read. That’s not a realistic option for a live system. The only practical solution is MVCC — keeping multiple versions of data so readers can see a consistent snapshot without blocking writers. MVCC requires the database engine to manage version visibility, which requires understanding transactions, which requires the full machinery of a database engine.
Failure mode #5: no query capability
This one is less dramatic than data corruption but responsible for an enormous amount of unnecessary work in every pre-database codebase that has ever existed.
Finding all customers in a specific city with a balance above a threshold requires reading every byte of the file, parsing every record, and applying the filter in application code. Adding a new filter adds more code. Joining two files — finding orders where the customer’s region is “West” — requires reading both files in their entirety and implementing the join logic by hand.
There’s no index. There’s no query language. There’s no planner that chooses the efficient path. Every query is a full table scan. Every join is an O(n×m) nested loop unless you hand-write a more efficient algorithm. Every new question requires new code. The query logic is tangled into the application code, which means it can’t be optimised, profiled, or reused across applications.
SQL exists because this is not a sustainable model at scale. Relational algebra gives you a declarative way to express what you want without specifying how to get it. The query planner figures out the how — choosing indexes, join algorithms, and parallel execution strategies based on the data’s actual statistics. The engineer asks the question; the engine figures out the efficient path.
The invisible tax of queryless data: Without queries, you can’t answer ad hoc questions. A product manager asks “how many users in Europe placed more than three orders in the last 30 days?” Without SQL, answering this requires a developer to write a script, run it overnight, and deliver results tomorrow. With SQL, it’s a one-liner. The queryability of data is not a convenience — it’s what makes the data useful to the business in real time.
Failure mode #6: no schema enforcement
A flat file is a sequence of bytes. There is nothing in the file itself that enforces that byte positions 12–19 contain a valid date, or that byte positions 20–27 contain a positive integer, or that a specific field references a valid record in another file. The enforcement — if it exists at all — lives in the application code.
This creates a slow-moving disaster. Application code changes. Teams change. Years pass. The original enforcement logic gets rewritten, or moved, or accidentally removed. A new application that reads the file doesn’t know to apply the same rules. Bugs slip through that write invalid data — a negative balance, a null customer ID, a date in the wrong format. The file silently accumulates invalid records over years.
When you try to query this data, you find inconsistencies. Some records are missing required fields. Some foreign key relationships don’t resolve. Dates are in three different formats across different time periods. This is called data rot, and it’s endemic in any system that stores structured data without schema enforcement.
The referential integrity problem: A flat file can’t enforce that an order’s customer_id refers to an existing customer. If a customer is deleted but their orders remain, those orders are orphaned — they reference a customer that doesn’t exist. In a flat file system, this is a bug that depends entirely on application-level discipline. In a relational database, FOREIGN KEY constraints make this class of bug structurally impossible.
Putting it together: ACID maps directly to the six failures
Now that you’ve seen all six failure modes, the four ACID properties have an obvious motivation:
ACID propertyFailure mode it preventsAtomicityFailure #2 — half-written multi-step operationsConsistencyFailure #6 — schema violations and referential integrity violationsIsolationFailure #4 — concurrent readers seeing each other’s intermediate statesDurabilityFailure #3 — crash recovery, no ambiguity about which writes survived
Failure #1 (concurrent write corruption) is prevented by isolation’s locking mechanisms. Failure #5 (no query capability) is addressed by the relational model and SQL, which we’ll cover in issue #010.

None of these properties are features that database engineers added for fun. Each one is the minimum engineering required to prevent a specific, documented class of data loss that happened repeatedly in real systems before databases existed. When a configuration knob in your database is labeled
synchronous_commitorfsyncorisolation_level, you are looking at the knob that controls exactly how strongly the database enforces one of these properties — and what performance you trade for that strength.
What came before relational databases
The flat file problem was recognised early. The 1960s saw two major attempts to address it before the relational model arrived.
Hierarchical databases (IMS, 1966): IBM’s Information Management System organised data in tree structures — parent records with child records, accessible by navigating the tree from root to leaf. It solved the concurrency and recovery problems (IMS had proper transaction management) but made certain queries — especially those that didn’t follow the hierarchy — extremely expensive or impossible. Querying across branches of the tree required full scans.
Network databases (CODASYL, 1969): The Conference on Data Systems Languages proposed a more general graph model — records connected by named sets (links), navigated by a cursor-based API. More flexible than hierarchical, but still navigational: you write code that walks the graph, rather than declaring what you want. Adding a new access path to the data required redesigning the schema.
Both solved the data corruption problems. Neither solved the query problem or the schema rigidity problem. Both required application code to know the physical structure of the data — which table was the parent, which link to follow — making the application tightly coupled to the storage layout.
Edgar CODD’s 1970 paper, “A Relational Model of Data for Large Shared Data Banks,” proposed the answer. We’ll cover it in full in the next issue.