
IMS, CODASYL & CODD's relational model — what came before SQL, why it failed, and the idea that changed everything
In 1970, a mathematician at IBM wrote an 11-page paper that made two decades of database engineering obsolete. Not because the old systems were badly built — they were engineering marvels.

The year is 1966. NASA is three years away from putting a man on the Moon. The Apollo programme is the largest engineering project in human history, involving 400,000 people, 20,000 contractors, and roughly 10 million individual parts. IBM wins the contract to build the information system that tracks all of it — what part goes where, what’s been ordered, what’s in stock, what’s been installed on which spacecraft.
The system they build is called IMS: the Information Management System. It stores data in tree structures — hierarchies of parent and child records — and processes it with transaction management that prevents the data corruption problems we covered in issue #004. IMS works. It helps put humans on the Moon. Versions of it are still running in banks and airlines today, half a century later, processing billions of transactions annually.
IMS is also, by the measure of what came after it, a design with a fundamental flaw. Not in its engineering — the engineering is superb. The flaw is in its data model. And understanding exactly what that flaw is, and why it took until 1970 for someone to articulate the fix, is one of the most illuminating stories in the history of computing.
IMS: the hierarchical model
IMS organises data as a forest of trees. Every record type is either a root or a child of exactly one parent type. A company has departments. A department has employees. An employee has projects. The physical storage on disk mirrors this hierarchy — children are stored near their parent, making navigation along the hierarchy fast.

The animated diagram builds the tree structure piece by piece: the company root, then department records branching from it, then employee records hanging from each department, then project assignment records below each employee. Each level is a different record type with its own fields. Navigation moves along the branches — to find an employee’s projects, you start at the root, navigate to the right department, navigate to the right employee, and then access their project children.
What IMS does well
Concurrent access and recovery. IMS had proper locking, transaction management, and crash recovery from the beginning. The flat file problems from issue #004 — concurrent write corruption, atomicity failures, no crash recovery — are all handled by IMS. It is a real database engine in the most important sense.
Hierarchical access is fast. If your access pattern follows the hierarchy — “give me all projects for this specific employee in this specific department” — IMS is very fast. Children are stored physically near their parents. Navigation along a known path is efficient.
Consistent, structured records. IMS enforces the schema. Records have defined fields with defined types. You can’t accidentally write a string into an integer field.
What IMS cannot do well
Cross-branch queries. The animated diagram shows this clearly. The query “find all employees currently working on the Apollo project” requires traversing every branch of the tree — every department, every employee within each department — and checking whether that employee has an Apollo project child. There is no way to go directly from a project name to the employees on it, because the hierarchy runs in one direction only: from company down to project. Going the other way means a full scan.
Multiple parent relationships. In reality, an employee might belong to multiple departments (a matrix organisation). A project might be assigned to employees across different departments. IMS trees cannot represent this. Each record has exactly one parent. Relationships that aren’t hierarchical require either data duplication (store the employee record in multiple departments) or a workaround that degrades the query performance IMS was designed to provide.
Schema changes. Adding a new field to the employee record type requires restructuring the physical storage of every employee record on disk. In a large IMS installation with millions of records, this is a multi-day offline operation. The application code that navigates the hierarchy is tightly coupled to the physical layout — change the layout, and you must find and update every program that touches those records.
The deeper problem, which IMS shares with all navigational databases, is this: the application code knows the physical structure of the data. Every program that reads or writes IMS records contains explicit navigation logic: go to this record type, follow this parent-child link, find this field at this byte offset. When the physical structure changes, every program that depends on it must change too.
CODASYL: the network model
In 1969, the Conference on Data Systems Languages — CODASYL — published a specification for a more general database model. Rather than limiting relationships to parent-child trees, the CODASYL model allowed any record to participate in multiple named sets — directed relationships between record types that could form arbitrary graphs rather than trees only.
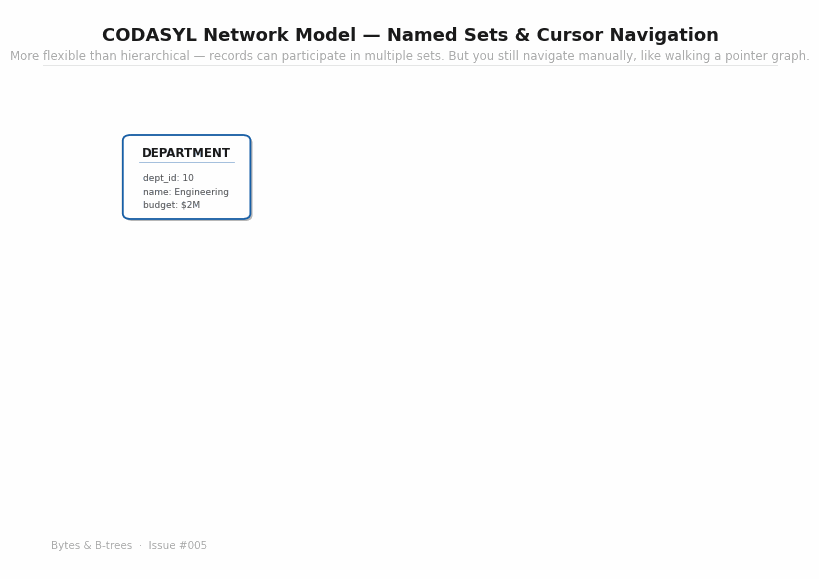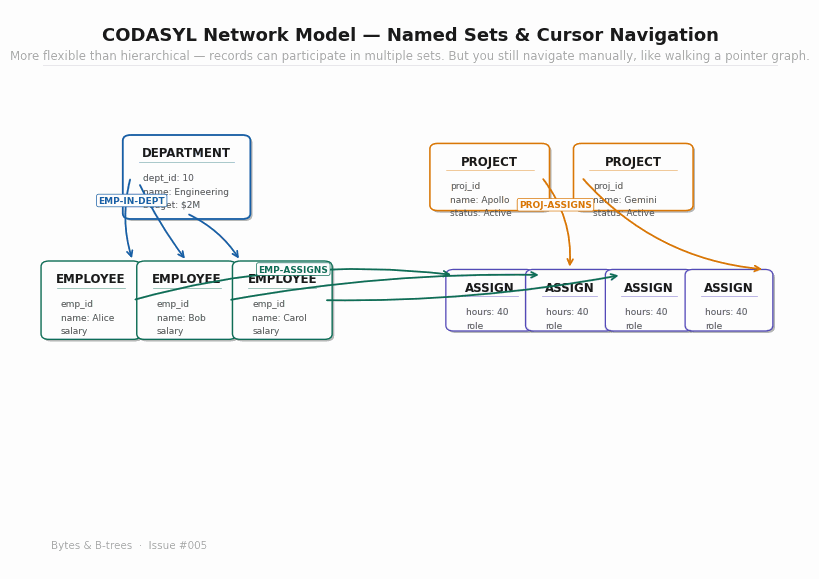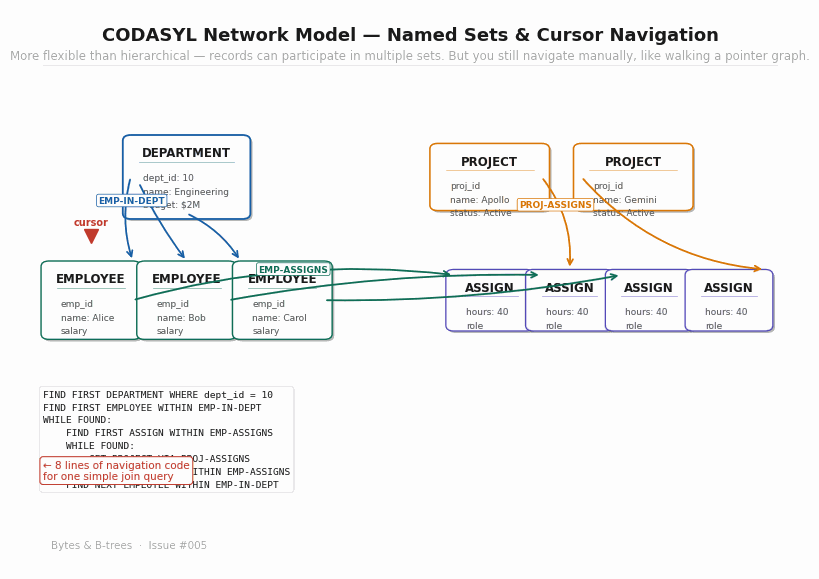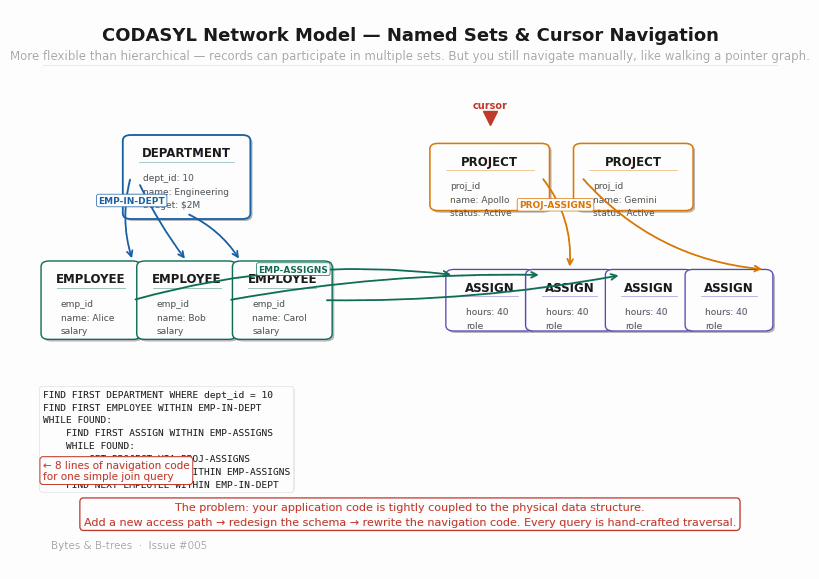
The animated diagram shows a CODASYL schema with DEPARTMENT, EMPLOYEE, PROJECT, and ASSIGNMENT record types. An EMPLOYEE belongs to the EMP-IN-DEPT set (owned by DEPARTMENT) and also participates in the EMP-ASSIGNS set (owned by ASSIGNMENT). An ASSIGNMENT participates in both EMP-ASSIGNS and PROJ-ASSIGNS. The graph is more expressive than a tree — an employee can have relationships to multiple departments, multiple assignments, multiple projects — all without data duplication.
What CODASYL improved over IMS
Many-to-many relationships. CODASYL could represent relationships that IMS required data duplication for. An employee on multiple projects, a project with employees from multiple departments — these are natural in the CODASYL model.
Richer query paths. Because relationships are bidirectional and an entity can participate in multiple sets, you can navigate from any direction. To find employees on the Apollo project, you start at the Apollo PROJECT record, follow the PROJ-ASSIGNS set, and reach all ASSIGNMENT records, from which you follow EMP-ASSIGNS backwards to reach the employees. No full-tree scan required.
What CODASYL didn’t fix
Look at the navigation code in the animated diagram:
FIND FIRST DEPARTMENT WHERE dept_id = 10
FIND FIRST EMPLOYEE WITHIN EMP-IN-DEPT
WHILE FOUND:
FIND FIRST ASSIGN WITHIN EMP-ASSIGNS
WHILE FOUND:
GET PROJECT VIA PROJ-ASSIGNS
FIND NEXT ASSIGN WITHIN EMP-ASSIGNS
FIND NEXT EMPLOYEE WITHIN EMP-IN-DEPTEight lines of code to answer what we would today express as a two-table JOIN. And this is the simple version — real CODASYL programs navigating complex schemas ran to hundreds of lines of cursor manipulation code.
The fundamental problem is unchanged from IMS: the application must know the physical structure of the data and navigate it explicitly. The programmer must know which set to follow, which direction to traverse, which record type sits at each position in the graph. The query specifies not what you want but how to physically retrieve it.
This creates what database historian C.J. Date called the navigation problem. When you want different data, you write different navigation code. When the schema changes, you rewrite all the navigation code that touched the changed portion. The application logic and the data structure are deeply entangled. There is no separation between the question being asked and the physical process of answering it.
The cursor-based interface
CODASYL uses a cursor — a pointer to a current record — as the primary interface. You move the cursor around the graph: FIND FIRST, FIND NEXT, GET CURRENT. The programmer explicitly manages cursor position throughout the program. This is not an abstraction — it exposes the physical navigation mechanism directly.
For a programmer who knows the schema and has written CODASYL code before, this is workable. For a business analyst who wants to ask an ad hoc question — “how many employees across all departments are assigned to Apollo?” — it is completely inaccessible. Only someone who knows the physical schema intimately can write the code to answer the question.
This was the state of the art in 1969. Then CODD wrote his paper.
CODD’s insight: separate the logical from the physical
Edgar F. CODD was a British mathematician working at IBM’s San Jose Research Lab when he published “A Relational Model of Data for Large Shared Data Banks” in the Communications of the ACM in June 1970. He was 39 years old. The paper is 11 pages. It changed everything.
CODD’s core insight sounds simple in retrospect: the logical structure of data should be independent of its physical storage.
IMS and CODASYL forced the programmer to know how data was physically laid out on disk — which record type was the parent, which set to follow, which pointer to dereference. This created an application dependency on physical structure that made schema changes expensive and ad hoc queries impossible for non-programmers.
CODD proposed that the database present data as a collection of simple, flat relations — what we now call tables. Each relation has named attributes (columns) and a set of tuples (rows). Relationships between tables are expressed by shared values (keys), not by physical pointers. The programmer expresses what data they want using operations on these relations. The database engine figures out the physical retrieval.
This separation is called data independence: the logical data model (tables and their relationships) is independent of the physical storage model (how those tables are laid out on disk, what indexes exist, how they’re partitioned). Change the physical storage — add an index, change the file layout, move data to a different disk — and the logical queries still work unchanged. The application code doesn’t know or care about the physical structure, because it never navigates it directly.
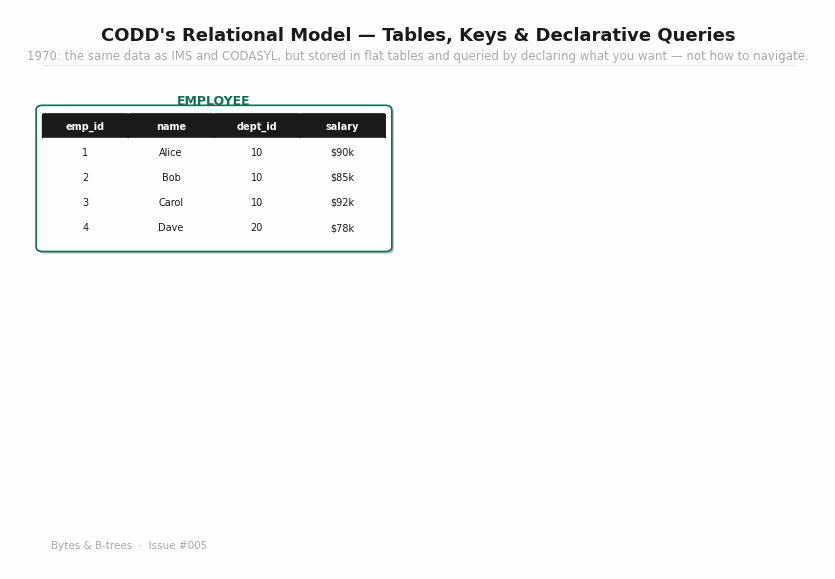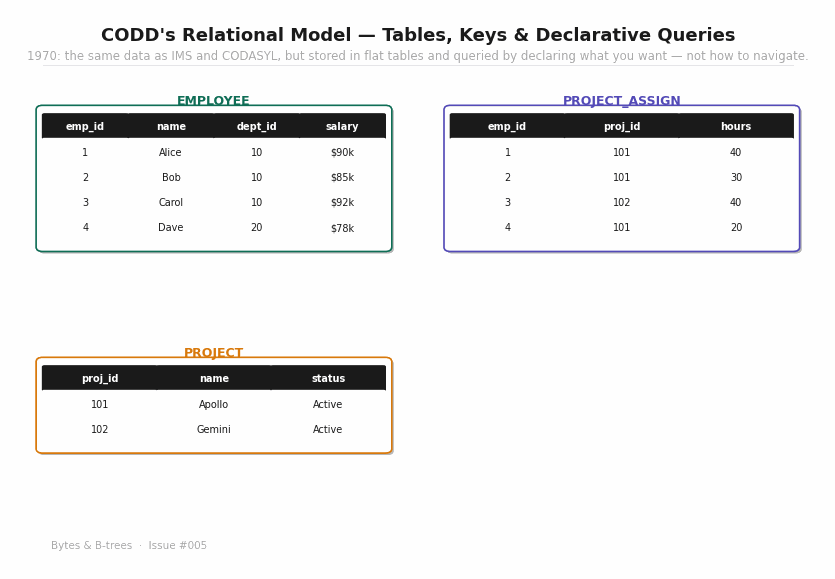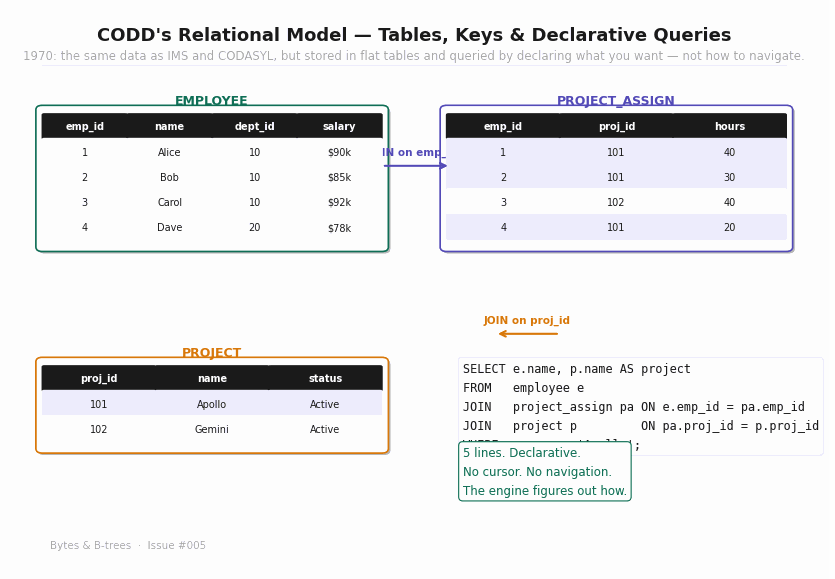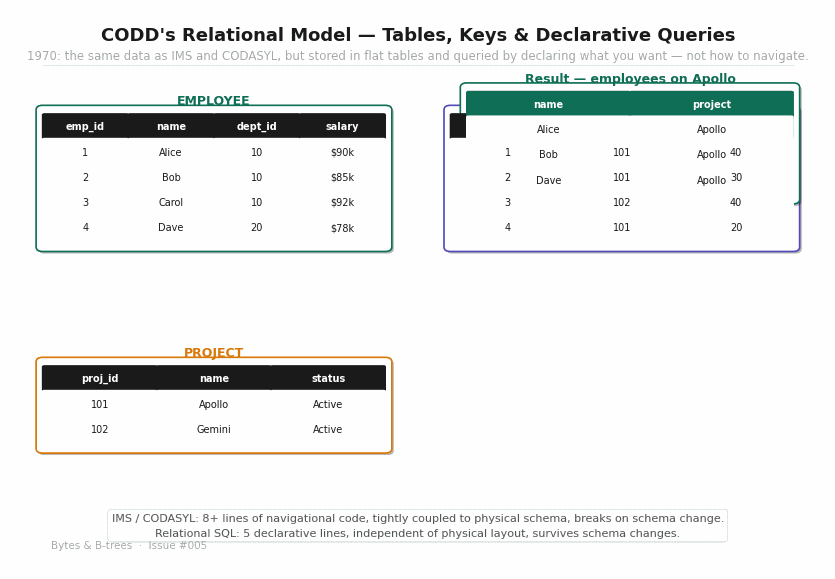
The animated diagram shows the same data from the IMS and CODASYL examples — departments, employees, projects, assignments — reorganised into flat tables. EMPLOYEE has a dept_id foreign key referencing DEPARTMENT. PROJECT_ASSIGN connects employees to projects by value, not by pointer. To query across the tables, you write a JOIN expressed as equality on shared key values.
Relational algebra: the mathematical foundation
CODD didn’t just propose a data model — he grounded it in mathematics. The relational model is based on set theory and first-order predicate logic. A relation is a set of tuples, and queries are expressed as operations on sets: select (filter rows), project (choose columns), join (combine tables on a condition), union, intersection, difference.
This mathematical foundation has two important consequences.
First, queries have well-defined semantics. A SQL query has a precise mathematical meaning that is independent of how the database executes it. Two queries that express the same set-theoretic operation are guaranteed to produce the same result, regardless of which execution path the database chooses. In CODASYL, different navigation paths to the same data could — under certain concurrency conditions — produce different results.
Second, the query optimiser is possible. Because the logical query is separated from the physical execution, the database engine can choose different physical execution strategies for the same logical query — use an index or not, choose a hash join or a merge join, execute in parallel or sequentially — based on the actual data distribution. The programmer never has to specify the physical strategy. The engine picks it.
This is the crucial enabler of everything we’ll study in issues #030–#035: how a query planner transforms a logical query into an efficient physical execution plan. None of that is possible without data independence — the clean separation between what you ask for and how the database retrieves it.
What CODD’s paper actually said
The paper opens with a precise diagnosis of the problem:
“Future users of large data banks must be protected from having to know how the data is organized in the machine (the internal representation).”
This single sentence explains IMS, CODASYL, and every navigational database. Users — including application programmers — shouldn’t need to know the physical layout. They should express queries in terms of the data’s logical meaning.
CODD then introduces the relational model: relations as mathematical sets, normal forms to eliminate redundancy, and relational algebra as the query language. The paper defines the first, second, and third normal forms — the foundations of relational schema design we’ll cover in depth in issues #050 and #051.
The paper also introduces the concept that became the PRIMARY KEY: the notion that every tuple in a relation is uniquely identified by some minimal subset of its attributes, called the primary key. Duplicate rows aren’t allowed — a relation is a set, and sets don’t have duplicates.
And it introduces foreign keys: the mechanism by which one relation references another by value. An EMPLOYEE tuple’s dept_id value must match the dept_id of some DEPARTMENT tuple. This is not a pointer — it’s a constraint on values. The constraint can be checked without knowing where either tuple is physically stored.
Why IMS and CODASYL people resisted
CODD’s paper met substantial resistance, particularly from within IBM, where IMS was a commercial product with paying customers and an enormous installed base.
The main technical objection was performance. In 1970, computers were slow enough that the query optimisation overhead seemed prohibitive. Navigating a known path through an IMS hierarchy was faster than letting a general-purpose optimiser figure out a query plan. The IMS performance argument was legitimate — for the access patterns IMS was designed for, it was genuinely faster than early relational implementations.
The deeper resistance was organisational. Large organisations had invested heavily in IMS and CODASYL systems. The navigation code was written. The schemas were designed. The database administrators knew the systems intimately. The idea that all of it should be replaced by a new model — however elegant — was threatening.
CODD’s relational model took roughly a decade to move from paper to production. The first commercial relational databases — Oracle (then called Relational Software), IBM’s own DB2, and Ingres — arrived in the late 1970s and early 1980s. SQL, the language that implemented relational algebra in a syntax accessible to non-mathematicians, was standardised in 1986. By the early 1990s, relational databases dominated enterprise computing. IMS and CODASYL systems were legacy infrastructure.
The performance objection was resolved not by making relational systems slower — but by making hardware faster. By the mid-1980s, hardware had improved enough that a well-optimised relational query could outperform hand-written CODASYL navigation, because the optimiser could choose strategies that a human programmer wouldn’t have thought of.
What IMS and CODASYL got right that is still true
It’s easy to read this history as “IMS and CODASYL were bad and the relational model was good.” That’s too simple.
Transaction management. IMS had proper ACID transactions before the relational model was even proposed. The need for atomicity, consistency, isolation, and durability was understood and implemented in hierarchical and network databases. The relational model inherited this; it didn’t invent it.
Physical data organisation still matters. The relational model achieves data independence at the logical level — your SQL query doesn’t specify the physical access path. But the physical storage still exists, and it still matters enormously for performance. When we study B-trees in issue #018, we’ll see that the physical organisation of data on disk — how related rows cluster together, how indexes are structured — determines query performance just as much as it did in IMS. The difference is that modern databases let the programmer express the logical query without specifying the physical path, while still allowing the physical structure to be tuned separately.
The navigational access pattern is sometimes right. There are workloads — graph traversals, recursive hierarchies, certain time-series access patterns — where navigating explicit relationships is genuinely more efficient than joining flat tables. This is part of why graph databases exist today. The relational model is not always the right model. But it is the right default, for most workloads, most of the time.
CODD’s insight wasn’t that navigation was wrong — it was that navigation shouldn’t be the programmer’s responsibility. The database should choose the navigation path. The programmer should express what they want. That separation of concerns is what made relational databases the foundation of modern data infrastructure.