
Files, block devices & the OS abstraction — and the three places where it leaks
A database doesn't see platters or flash cells. It sees files. The operating system promises that files are a clean, simple interface to whatever storage hardware sits underneath.

There’s a mental model most engineers carry about how files work: you open a file, you write bytes, you close it, those bytes are on disk. Clean. Simple. Abstracted.
That model is accurate enough for writing a log file or saving a configuration. For a database engine managing hundreds of gigabytes under concurrent write load, it breaks down in three specific places — and each place is a source of bugs, data loss, and performance degradation that has burned real systems in production.
This issue is about those three leaks. Not because database engineers need to fix the OS — they don’t — but because understanding where the abstraction breaks explains every unusual thing databases do when writing and reading files. The WAL, the fsync dance, the pre-allocation of large extents, the
O_DIRECTflag, the careful tuning ofcheckpoint_completion_target— all of it makes immediate sense once you see what the OS abstraction doesn’t actually guarantee.
From filename to bytes: the three-layer translation
When Postgres opens its main data file, the OS doesn’t just hand it a pointer to raw bytes on disk. It translates the filename through three distinct layers before a single byte flows.

Layer 1: directory entry → inode
The filename pg_data is stored in a directory entry — a simple mapping from a human-readable name to an inode number. An inode is a fixed-size data structure stored at a known location on the filesystem. It contains the file’s metadata (size, permissions, timestamps, ownership) and, critically, the list of block addresses where the file’s actual data is stored.
This separation — name from inode, inode from data — is deliberate. It means a file can have multiple names (hard links) pointing to the same inode. It means renaming a file is cheap (you just update the directory entry) rather than requiring moving all the data. It means file metadata and data can be updated independently.
For databases, the inode layer creates a subtle constraint: renaming a file is atomic at the OS level, but creating a new file, writing data to it, and then renaming it to replace the old one is the standard pattern for safe file replacement — and whether the rename survives a crash depends on whether the directory entry write was fsynced. Databases doing crash-safe configuration file updates must fsync both the file and the directory containing it.
Layer 2: inode → block addresses
The inode contains a list of block addresses: the physical locations on disk where the file’s 4KB blocks live. In older filesystems like ext2, this was a literal array of block numbers, with indirect pointer blocks for large files. In modern filesystems like ext4, this uses an extent tree: instead of listing individual block numbers, the inode lists contiguous ranges (extents) like “blocks 4812 through 4847.” This is far more efficient for large files — a 1GB file might be described by a handful of extents instead of 262,144 individual block numbers.
The block addresses in the inode are what get handed to the block device layer for actual I/O. The filesystem translates “give me bytes 0–8191 of this file” into “read blocks 4812 and 4813 from the block device.”
Layer 3: block device → hardware
The block device layer presents a uniform interface: a linear array of numbered 4KB blocks. Whether the underlying hardware is an HDD, SSD, NVMe, or a RAID array, the filesystem sees the same interface. The device driver translates block numbers into hardware-specific commands (SCSI for HDDs, NVMe commands for NVMe drives).
This uniformity is what lets the same Postgres binary run on an HDD server, an NVMe-backed cloud instance, and a RAM disk with no changes. The database operates entirely in terms of file offsets; the OS translates everything below.
Abstraction leak #1: the page cache lie
This one we covered in issue #002, but it’s worth stating precisely in the context of the full abstraction stack.
The OS page cache sits between the filesystem and the hardware. When your database calls write(), data lands in the page cache — kernel-managed RAM — and the OS returns success immediately. The kernel schedules the actual disk write for later. From the application’s perspective, the write completed. From the hardware’s perspective, nothing happened yet.

The animated diagram shows the full lifecycle: a write() call fills pages in the kernel’s page cache (shown in amber as “dirty” pages), the OS returns success, the database celebrates a completed write — and then a power failure hits, and every dirty page in the cache is simply gone.
Why the OS does this: Batching writes is genuinely faster. If your application writes a 100-byte record every millisecond, and the OS flushed each write to disk immediately, you’d be doing 1,000 fsync() operations per second, each costing 500µs–30ms depending on hardware. Instead, the OS accumulates dirty pages and flushes them in larger, more efficient batches. For most applications — web servers, log writers, configuration tools — this is the right trade-off. Durability is less important than throughput.
For a database that has promised “I won’t lose your data if the power goes out,” it’s the wrong trade-off. Databases solve this by calling fsync() on specific files at specific times — specifically, after writing to the WAL and before acknowledging a commit. The WAL is append-only and sequential, so fsync() on the WAL file is as fast as fsyncing gets on a given piece of hardware.
The O_DIRECT alternative: Some databases bypass the page cache entirely using the O_DIRECT file flag. Writes with O_DIRECT go directly from the database’s buffer pool to the storage hardware, skipping the OS page cache entirely. This eliminates double-buffering (the same data in both the database buffer pool and the OS page cache), gives the database precise control over what’s in memory, and removes the “dirty page accumulation and background flush” unpredictability.
The trade-off: with O_DIRECT, the database is solely responsible for durability. There’s no OS page cache copy to fall back on. The WAL and recovery mechanisms must be airtight. This is fine for a production-grade database engine, but it means there’s no safety net. MySQL’s InnoDB uses O_DIRECT by default. Postgres defaults to using the OS page cache but can be configured otherwise.
Abstraction leak #2: block alignment
The OS block size and the database page size are not always the same number.
Linux uses 4KB blocks by default. Postgres uses 8KB pages. MySQL InnoDB uses 16KB pages. When a Postgres page is written, it occupies exactly two OS blocks. When an InnoDB page is written, it occupies four. As long as both layers agree — a database page is always written as a complete set of OS blocks — this is fine.
The problem is what happens if the write is interrupted halfway. If a system crash occurs while Postgres is writing an 8KB page that spans OS blocks 4812 and 4813, the crash might leave block 4812 with new data and block 4813 with old data. The two halves of the same database page are now from different points in time. This is called a torn write, and it is a form of corruption that the database’s recovery system must detect and handle.
How ext4 and XFS handle this: Modern filesystems running in their default journaling modes provide atomicity guarantees at the OS block level — a single 4KB block write is atomic. But database pages that span multiple blocks don’t get atomicity for free. The two-block write of a Postgres 8KB page is not guaranteed to be all-or-nothing.
How Postgres handles this: InnoDB addresses torn writes with the doublewrite buffer — a technique where pages are written to a known-safe region of the disk before being written to their final location, so a torn write in the final location can always be repaired from the doublewrite buffer copy. We’ll cover this in detail in issue #042.
Postgres relies on the WAL instead. Even if a torn write leaves a page half-corrupted, the WAL contains a full record of what the page should look like after recovery. On restart, Postgres replays the WAL and reconstructs any pages damaged by torn writes. The WAL record takes priority over whatever is on disk.
The practical implication for schema design: This is why some PostgreSQL configurations write full-page images to the WAL after checkpoints. The setting full_page_writes = on (default: on) tells Postgres to write the entire 8KB page to the WAL the first time that page is modified after a checkpoint. This ensures that even if the page is torn during a crash, the full original page image is available in the WAL for recovery. It increases WAL volume by potentially a lot, but it’s the correct default for production.
Abstraction leak #3: fragmentation
The filesystem abstraction promises that a file is a sequence of bytes. It doesn’t promise that those bytes are stored in physically contiguous locations on the storage device. They usually aren’t, and the implications for database performance are severe.
What fragmentation actually means
When the OS allocates blocks for a file, it takes whatever free blocks are available — not necessarily contiguous ones. On a filesystem with lots of activity (other processes creating and deleting files, the database itself allocating and freeing space), a file being extended block by block ends up with its blocks scattered across the disk. This is fragmentation.
For SSDs, fragmentation matters much less. There’s no physical head movement — the device can access any block in ~50–150µs regardless of its physical location. The difference between accessing adjacent blocks and blocks at opposite ends of the device is in the noise.
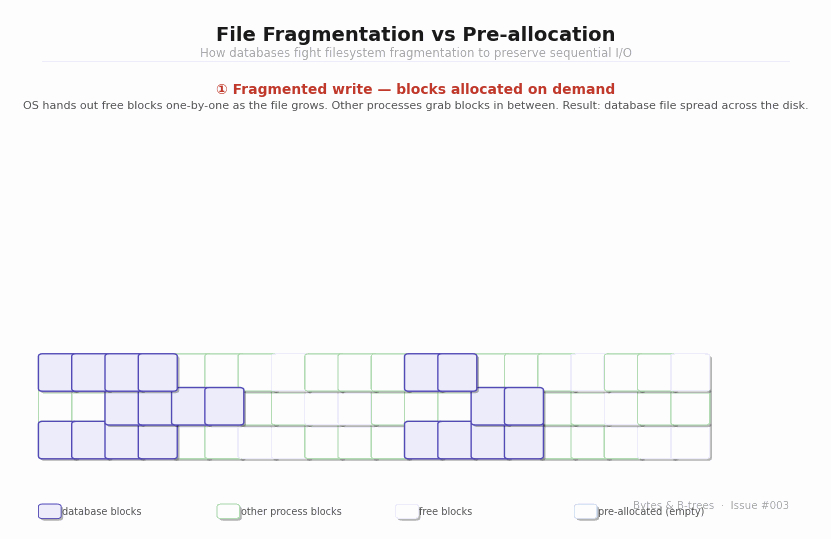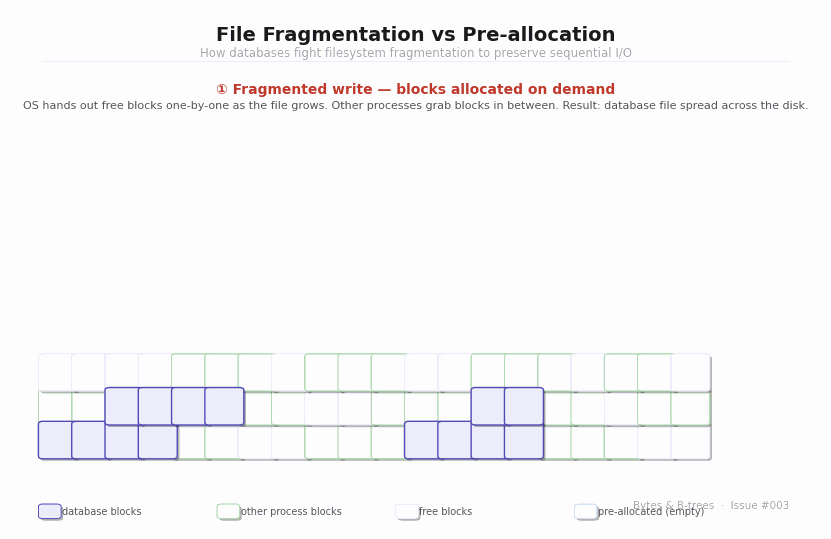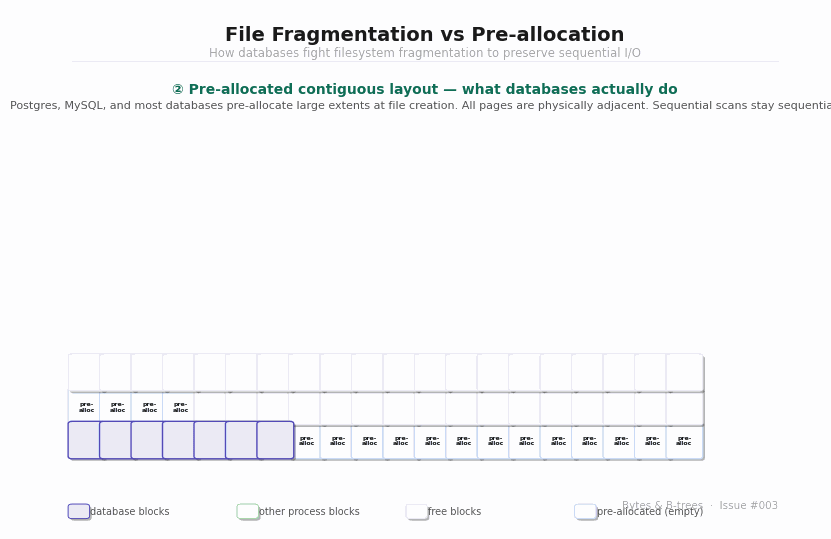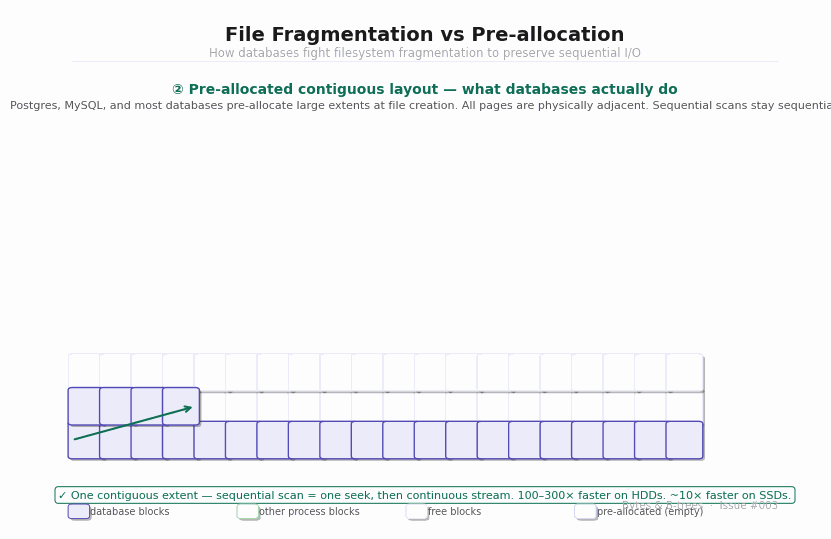
For HDDs, fragmentation is catastrophic for performance. A sequential scan of a fragmented file is not actually sequential — the disk head must seek between each fragmented extent, paying the full 5–15ms seek penalty each time. A file with 50 fragments requires 50 seeks. What should be a 1-second sequential scan becomes a 50-second seek-dominated crawl.
What databases do about it: pre-allocation
Rather than letting the OS allocate blocks on demand as the file grows, databases pre-allocate large contiguous extents upfront. When Postgres creates a new table segment or extends an existing one, it doesn’t ask for 8KB — it asks for 1MB or more at once, claiming a contiguous block of disk space before writing any data to it. The OS, finding a large free contiguous region, allocates it as a single extent.
This means the file’s blocks are physically adjacent on disk. When Postgres later does a sequential scan of the table, it’s a true sequential read — one seek, then continuous streaming data at full disk throughput.
How Postgres pre-allocates: Postgres extends relation files in chunks defined by the BLCKSZ compile-time constant (8KB by default) but writes them in segments up to 1GB (RELSEG_SIZE). The pg_prewarm extension and the OS’s posix_fallocate() system call can pre-allocate disk space without writing data, reserving contiguous blocks immediately.
WAL files: the most important case: The WAL is perhaps the most fragmentation-sensitive file in the entire database. Every commit that requires fsync() writes to the WAL, and WAL write latency is directly in the commit latency path. Postgres pre-allocates WAL segment files (16MB by default, configurable with wal_segment_size) and keeps a small number of pre-allocated segments ready at all times. This ensures that WAL writes are always sequential into pre-allocated space — never waiting for the OS to find and allocate new blocks mid-write.
The wal_keep_size parameter controls how many WAL segments to retain for replication standbys, and max_wal_size controls when checkpoints are forced. Getting these right for your workload is one of the first things to tune on a busy write-heavy database.
How the three leaks combine: a production scenario
Consider a Postgres server under heavy write load. A bug in the application causes a large transaction to hold an open cursor for two hours. During those two hours:
Leak #1 (page cache): The page cache has been accumulating dirty pages for the table being modified. Because the long transaction holds back the oldest snapshot, VACUUM can’t clean the table. Dirty pages build up. Checkpoint is delayed. When the checkpoint eventually runs, it has to flush a large backlog of dirty pages to disk all at once — a write burst that saturates the storage device and causes a spike in commit latency for all other transactions.
Leak #2 (block alignment): During the checkpoint write burst, the server crashes mid-checkpoint. Some pages were written torn. On restart, Postgres replays the WAL from the last completed checkpoint. Because full_page_writes is on, it has the full pre-crash page images and can reconstruct everything correctly. Data loss: zero.
Leak #3 (fragmentation): The autovacuum process has been unable to reclaim space on the bloated table due to the long transaction holding back the snapshot. When the transaction finally ends, autovacuum runs aggressively, reclaiming and reusing free space in the table. Some of this reclaimed space is non-contiguous — the table is now fragmented. Future sequential scans pay a fragmentation penalty until a VACUUM FULL or CLUSTER operation is run to rebuild the table with contiguous storage.
None of these is a catastrophic failure. All three are the normal, expected operation of the database and filesystem working within their known constraints. But understanding the constraints is what lets you recognise each symptom, trace it to its source, and make the correct intervention.
The three tuning knobs these leaks explain
full_page_writes = on — Addresses leak #2. Writes full page images to WAL after checkpoints to enable recovery from torn writes. Leave this on unless you have hardware-level write atomicity guarantees (some enterprise storage controllers provide this).
checkpoint_completion_target = 0.9 — Addresses leak #1. Spreads dirty page flushing across 90% of the checkpoint interval rather than concentrating it at the end. Prevents write bursts. Set this to 0.7–0.9 on busy write workloads.
wal_segment_size — Addresses leak #3. Larger WAL segments mean fewer file allocations, less fragmentation, and more contiguous sequential writes. The default of 16MB is sensible; 64MB or 256MB is reasonable for write-heavy workloads on modern NVMe storage.
What’s actually behind pg_test_fsync
Postgres ships with a diagnostic tool, pg_test_fsync, that benchmarks fsync performance on your specific hardware. It tests different wal_sync_method options — fsync, fdatasync, open_sync, open_datasync — and reports the number of WAL writes per second achievable with each. The method that achieves the highest rate is the right choice for your hardware.
Run this before deploying a new database server. The right answer varies enormously by hardware. On some SSD configurations, fdatasync is 3–5× faster than fsync because it skips fsyncing file metadata changes. On others the difference is negligible. The only way to know is to measure.
bash
# Run as the postgres user on your actual server hardware:
pg_test_fsync -s 2
# Output example (your numbers will vary by hardware):
# Compare file sync methods using one 8kB write:
# (in wal_sync_method preference order, fastest first)
# open_datasync 3429.5/sec 291 usec/op
# fdatasync 3152.8/sec 317 usec/op
# fsync 2847.3/sec 351 usec/op
# fsync_writethrough n/a
# open_sync 2103.6/sec 476 usec/opThe winning method becomes your wal_sync_method in postgresql.conf.
The practical takeaway
The OS file abstraction is clean and useful — and it has three specific gaps that every serious database must work around:
Gap 1 — write() doesn’t mean “on disk.” fsync() does. Databases use the WAL pattern: write a compact sequential record, fsync it, then acknowledge the commit. The data pages follow asynchronously.
Gap 2 — Multi-block writes aren’t atomic. A crash mid-write leaves torn pages. Databases address this with either a doublewrite buffer (InnoDB) or full-page WAL writes (Postgres), so recovery always has a clean copy.
Gap 3 — The OS allocates blocks for throughput, not locality. Databases pre-allocate contiguous extents upfront — especially for WAL files — so that writes stay sequential and reads stay fast.
When you see any database configuration knob related to fsync methods, WAL sizing, checkpoint spreading, or pre-allocation — it’s addressing one of these three gaps. There’s no mystery. There’s just the physics of storage and the engineering required to work within it reliably.