
Issue #007 — Atomicity at the Byte Level

"Vault assets for this issue: wal_demo.py + fsync_benchmark.sh — accessible in your GitHub vault invitation."
“Atomic” comes from the Greek word for indivisible. In physics, atoms turned out to be very much divisible — protons, neutrons, electrons, quarks. But in databases, atomicity holds. A transaction either commits completely or leaves no trace whatsoever. This issue explains exactly how that guarantee is built from write operations that are individually not atomic at all.
Here is a fact that should immediately raise a question: a write() system call is not atomic. You can write 8KB to a file and have the system crash after the first 4KB have been persisted. The storage hardware itself is not atomic — it has no concept of “complete this set of writes or undo all of them.” And yet, when Postgres tells you a transaction committed, you can be absolutely certain that either all of its changes are reflected in the database or none of them are. Not most of them. Not the first three of five updates. All, or none.
How is a non-atomic property — atomicity — built from hardware primitives that aren’t atomic?
The answer is one of the most elegant pieces of systems engineering in all of database design. It doesn’t require any hardware support beyond what we described in issue #001. It doesn’t require locking data pages. It doesn’t require any special hardware atomic instructions. It requires only the write-ahead log, two types of information stored in each log record, and a clear protocol for which writes happen in which order.
This issue traces a transaction from BEGIN to COMMIT (and from BEGIN to ROLLBACK) at the byte level — every write, every fsync, every piece of state that must exist for the guarantee to hold.
The transaction state machine
Before we go to bytes, we need the conceptual model. Every transaction moves through a precise sequence of states. The guarantee of atomicity is that no intermediate state is ever observable to another transaction.
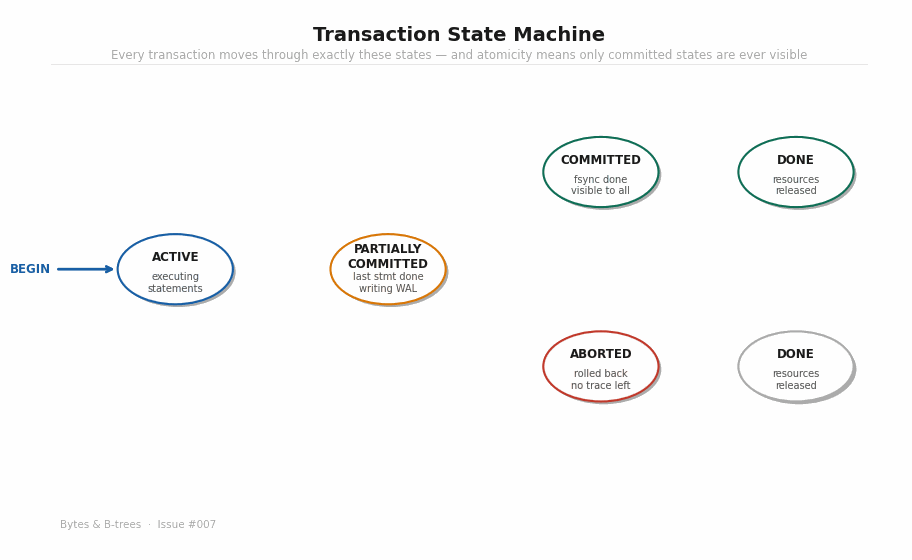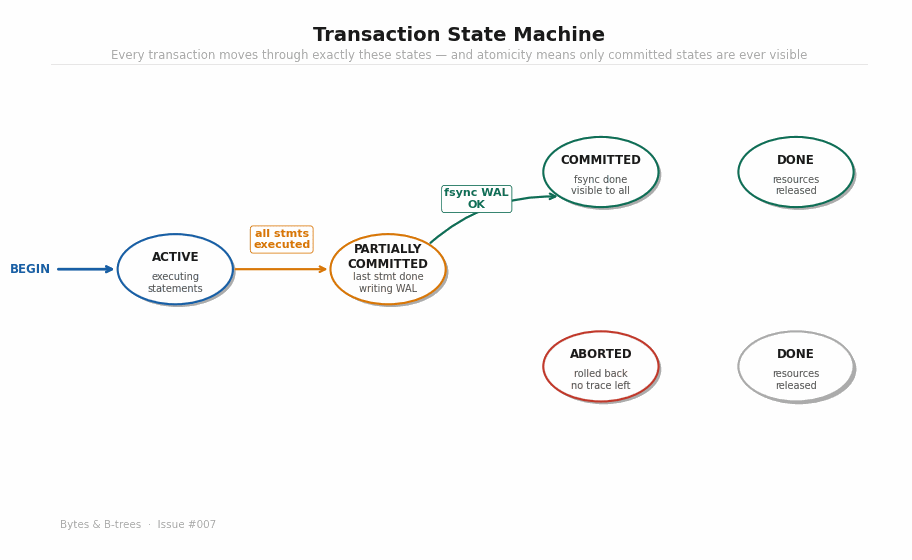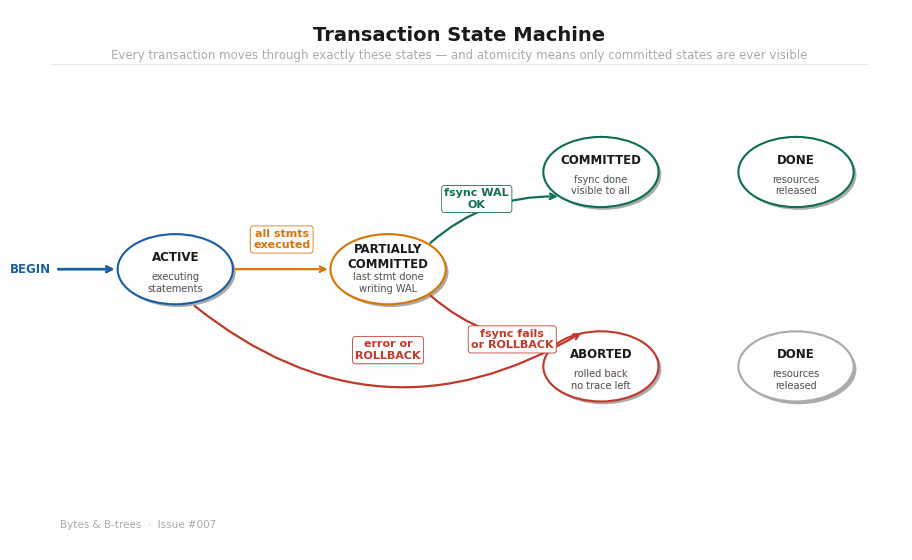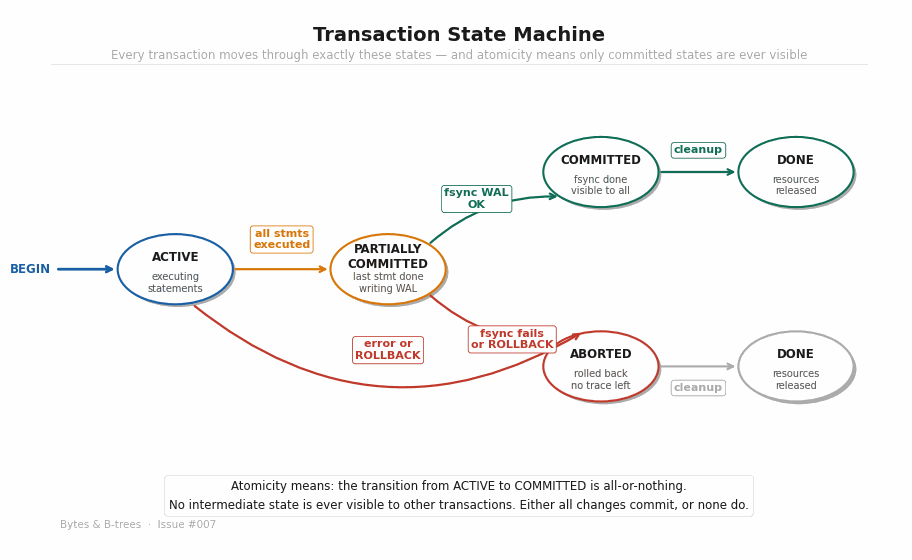
The animated diagram builds the state machine step by step:
ACTIVE — The transaction is executing SQL statements. It’s reading and writing rows. Everything is happening in memory (shared_buffers) and in WAL buffers. Nothing is on disk yet. From the outside, none of these changes are visible.
PARTIALLY COMMITTED — The transaction has executed its last statement. All WAL records for the transaction have been written to the WAL buffer in memory. The system is about to fsync.
COMMITTED — The WAL has been fsynced to disk. The COMMIT record exists in durable storage. This is the point of no return. The transaction’s changes will survive any subsequent crash. And only now — not before — are the changes visible to other transactions.
ABORTED — Either the application issued ROLLBACK, or an error occurred, or the fsync failed. The transaction is being unwound. No changes from this transaction should be visible to anyone, ever.
DONE — Resources released, locks dropped, transaction ID freed for reuse.
The critical insight is the gap between PARTIALLY COMMITTED and COMMITTED. In that gap, the transaction has finished executing, but its changes are not yet durable and not yet visible. The fsync is what bridges the gap. Before the fsync, the transaction is in a liminal state — it’s done from the application’s perspective, but the database is still making it permanent.
The application blocks at COMMIT until the fsync completes and the state transition to COMMITTED is confirmed. This is why commit latency on an HDD is 10–30ms: the application is waiting for physical confirmation from the storage device.
What is actually written to the WAL
The WAL is a sequential append-only file. Every change to every data page generates one or more WAL records. The records are written in strict order. Let’s look at exactly what’s inside one.

LSN (Log Sequence Number) — 8 bytes. A monotonically increasing identifier for this position in the WAL stream. LSNs are how Postgres tracks “how far has this replica replicated?” and “from which point does recovery need to replay?” Every WAL record has a unique LSN. You can query the current WAL LSN in Postgres with SELECT pg_current_wal_lsn().
Transaction ID (XID) — 4 bytes. Which transaction produced this record. Postgres uses 32-bit transaction IDs, which is why transaction ID wraparound (the famous “XID wraparound” issue) is a real operational concern — running out of 32-bit XIDs would mean the database could no longer distinguish old from new.
Record type — 1 byte. HEAP_INSERT, HEAP_UPDATE, HEAP_DELETE, XLOG_XACT_COMMIT, XLOG_XACT_ABORT, and others. The record type tells the recovery process what operation to replay or undo.
Relation OID and block number — Which table (by object identifier) and which 8KB page within that table was modified.
Before-image (old tuple) — The complete state of the row before this change. Variable length. This is the undo information. If the transaction must be rolled back, Postgres applies this image to restore the row to its pre-transaction state.
After-image (new tuple) — The complete state of the row after this change. Variable length. This is the redo information. If the system crashes after the WAL record is written but before the data page is written to disk, recovery replays this image to reconstruct the correct data page state.
CRC — A 32-bit checksum over the entire record. On recovery, Postgres verifies the CRC before replaying any record. A corrupted WAL record stops recovery rather than applying corrupt data.
The presence of both before-image and after-image in the same record is the key to atomicity. The after-image enables redo (crash recovery forward). The before-image enables undo (rollback). Both directions of atomicity — completing and cancelling — are possible from a single log record.
The exact commit sequence: what happens in what order
Let’s trace a specific transaction to its individual write operations. The transaction:
BEGIN;
UPDATE accounts SET balance = balance - 100 WHERE id = 42;
UPDATE accounts SET balance = balance + 100 WHERE id = 99;
COMMIT;Here is every write, in order, with nothing omitted:
Step 1 — BEGIN received. A transaction ID (XID) is allocated from shared memory. A BEGIN WAL record is written to the in-memory WAL buffer. The data pages for accounts 42 and 99 are loaded into shared_buffers from disk (if not already cached). Nothing has been written to disk.
Step 2 — First UPDATE executes. Postgres reads the current tuple for account 42 from shared_buffers. It creates a new tuple in the same or a nearby page with balance = old_balance - 100. Both tuples now exist in the page (this is MVCC — the old version for readers, the new version for this transaction). A WAL record is written to the in-memory WAL buffer: before-image is the old account 42 tuple, after-image is the new account 42 tuple.
Step 3 — Second UPDATE executes. Same process for account 99. WAL record written to buffer.
Step 4 — COMMIT received. This is where atomicity is established:
a) Write COMMIT WAL record to WAL buffer
b) Flush WAL buffer to WAL file on disk (write() + fsync())
← THIS IS THE BLOCKING OPERATION. Application waits here.
c) fsync() returns: storage device confirms data is durable
d) COMMIT returns to the application: “Transaction committed”
The data pages for accounts 42 and 99 in shared_buffers are still dirty — they haven’t been written to the data files on disk. The background writer process will eventually flush them, but not in the commit path.
Step 5 — Data pages flushed asynchronously. The background writer process or the checkpoint process flushes the dirty pages to their data files. This happens after the commit and is not visible to the committing transaction. It may happen milliseconds or minutes after the commit, depending on load.
Now here is the critical question: if the machine crashes between Step 4 and Step 5 — after the WAL is durable but before the data pages are written to disk — what happens on recovery?
Postgres opens the WAL file, finds the COMMIT record for XID 7421, sees that there is a committed transaction whose data page changes are not yet reflected in the data files, and replays the after-images from the WAL records for each UPDATE. The data pages end up in exactly the state they would have been in had the machine not crashed. The transaction is complete. Nothing is lost.
This is redo recovery. The WAL is always written before the data pages. This ordering — WAL before data — is the core invariant of write-ahead logging. It’s why the mechanism is called write-ahead: the log is always written ahead of the data.
How ROLLBACK works without a second disk write
Now let’s trace a rollback:
BEGIN;
UPDATE accounts SET balance = balance - 100 WHERE id = 42;
-- Something goes wrong
ROLLBACK;
After the UPDATE, the situation is:
shared_buffers has the modified page for account 42 (balance = 900 in the new tuple)
The WAL buffer has a WAL record with before-image (1000) and after-image (900)
The data file on disk still has the original value (balance = 1000) — the async write hasn’t happened yet
When ROLLBACK is issued:

Step 1 — Postgres writes an ABORT WAL record to the WAL buffer. This marks the transaction as aborted. It does not need to be fsynced immediately (though it will be written to disk eventually) — an uncommitted transaction’s changes are never visible to other transactions, so there’s no data loss if the ABORT record is lost in a crash.
Step 2 — Postgres reads the before-image from the WAL buffer (in memory — no disk read required). For account 42, the before-image is balance = 1000.
Step 3 — Postgres writes the before-image back into the shared_buffers page, overwriting the new tuple’s data. The page now has balance = 1000 again — the pre-transaction state.
Step 4 — The new tuple (balance = 900) is marked as dead. VACUUM will eventually reclaim its space.
That’s it. ROLLBACK is fast because:
The data file was never touched — there’s nothing to undo there
The before-image is in the WAL buffer, which is in memory
Restoring the before-image is a single memory write
No disk read. No disk write (beyond the ABORT WAL record). No seeking through the data file. Rollback’s cost is proportional to the number of rows modified, not to the size of the table.
The misconception about ROLLBACK: Many engineers assume ROLLBACK “reverses” the writes to disk. It doesn’t. It reverses the writes to shared_buffers. The disk was never involved. The WAL’s before-image is the mechanism that makes this possible — it stores the undo information alongside the redo information in the same record, so both directions of recovery are available without any additional state.
Why the WAL must be fsynced before data pages
There is a precise ordering requirement in write-ahead logging that, if violated, destroys the atomicity guarantee. Let’s examine what would happen if data pages were written to disk before the WAL was fsynced.
Scenario: Postgres writes the modified account 42 data page to disk (balance = 900), then crashes before the WAL is fsynced.
On recovery: Postgres reads the data file. It sees balance = 900 for account 42. It looks at the WAL for any un-replayed transactions. It finds... nothing (the WAL wasn’t fsynced). Postgres concludes: “This data is consistent — there are no WAL records to replay.” But the data is not consistent. Account 42’s balance was changed by a transaction that was never committed. The change is permanent, and there’s no record of what the original value was.
This is a violation of atomicity: a transaction’s changes are visible even though the transaction was never committed.
The only way to prevent this is the WAL-before-data ordering:
WAL records for the transaction are written and fsynced
Only after the WAL is durable can data pages be written to disk
Postgres enforces this through a protocol called WAL-logged page writes. Before any dirty page is flushed to disk, Postgres checks that all WAL records that describe changes to that page have been written to disk. This is tracked per page using the page’s LSN: the page stores the LSN of the most recent WAL record that describes a change to it. The background writer will not flush a page to disk until the WAL has been flushed to at least that page’s LSN.
The full_page_writes parameter in Postgres tightens this further: after a checkpoint, the first modification to a page writes the entire page image to the WAL (not just the change). This is the full-page write. It ensures that even if a page is torn during writing (half-written to disk, then crash), the WAL contains the complete before-and-after state needed to reconstruct the page correctly.
Savepoints: atomicity within atomicity
SQL supports savepoints — named points within a transaction to which you can partially roll back:
BEGIN;
UPDATE inventory
SET quantity = quantity - 10
WHERE sku = 'WIDGET';
SAVEPOINT after_inventory;
UPDATE orders
SET status = 'confirmed'
WHERE id = 9901;
-- This fails with a foreign key violation
ROLLBACK TO SAVEPOINT after_inventory;
-- The inventory update survives; the orders update is undone
COMMIT;Savepoints are implemented exactly like full transaction rollback, but scoped. When a savepoint is created, Postgres records the current WAL LSN as the savepoint boundary. If a rollback to savepoint is requested, Postgres applies before-images from WAL records written after that LSN — only those records, not the ones written before the savepoint.
The WAL’s sequential structure makes this straightforward: records before the savepoint LSN are left alone; records after the savepoint LSN are undone using their before-images. The transaction continues as if the rolled-back portion never happened.
This is also why long transactions that modify many rows are expensive to roll back — Postgres must apply before-images for every WAL record written during the aborted portion. The cost is proportional to the work done, not to the table size, but for a transaction that has modified a million rows, that’s a million before-image applications.
The synchronous_commit lever
There’s a performance escape hatch that’s worth understanding in this context: synchronous_commit.
When synchronous_commit = on (the default), Postgres waits for the WAL fsync before returning COMMIT to the application. This is the full guarantee: committed transactions survive any crash.
When synchronous_commit = off, Postgres returns COMMIT to the application before the WAL is fsynced. The WAL will be fsynced shortly afterward (within wal_writer_delay, default 200ms), but the application gets its commit confirmation first.
The risk: if the machine crashes in the window between the application receiving COMMIT and the WAL being fsynced, that transaction’s changes are lost. The database will not be corrupted — the WAL is consistent, just missing the very recent transactions. But those transactions are gone, despite the application having been told they committed.
For workloads where occasional data loss is acceptable (logging, metrics, analytics ingestion), synchronous_commit = off can increase write throughput dramatically — it turns what would be 1,000 sequential fsyncs per second (each blocked, each waiting for storage confirmation) into a much smaller number of batched fsyncs.
For any workload involving financial data, user-visible state, or any operation where “committed” must mean durably committed, leave synchronous_commit = on.
The parameter can even be set per-session or per-transaction, letting you mix durability levels within a single application:
-- For this session only: high-durability mode
SET synchronous_commit = on;
BEGIN;
INSERT INTO payments VALUES (...);
COMMIT; -- blocks until fsynced
-- For this session only: high-throughput mode
SET synchronous_commit = off;
BEGIN;
INSERT INTO page_views VALUES (...);
COMMIT; -- returns immediately, fsync happens within 200msThe practical mental model for atomicity
Atomicity is not a property of storage hardware. It’s a property of protocol.
The WAL protocol achieves atomicity through three rules:
Write WAL records before data pages
Write COMMIT to WAL (and fsync) before acknowledging commit to the application
On recovery, replay all WAL records for committed transactions; apply before-images for all uncommitted transactions
If these three rules are followed, any crash at any point leaves the database in a state where every visible transaction is fully committed and every non-visible transaction has left no trace. The atomicity guarantee holds regardless of when the crash occurs — before the WAL is written, mid-WAL write, after the WAL but before the data pages, mid-data-page write, at any point.
This is why “add a WAL” is not just a database feature — it’s the engineering solution to the fundamental impossibility of atomic writes on hardware that doesn’t support them natively. And it’s why almost every storage system that needs durability — databases, distributed file systems, operating system journals, even the internal state machines of SSDs — uses some variant of this pattern.
