
172 issues, completely mapped — every concept, every track, every connection

This is the syllabus. All three years. Everything we’ll cover, in order, with enough detail that you can decide whether this newsletter is right for you before reading a single issue.
Bytes & B-trees | Pre-launch #3 of 3 | Free | Bookmark recommended
Most online courses and newsletters launch with a vague promise: “we’ll cover everything you need to know.” This is not that.
What follows is the exact plan for every issue of Bytes & B-trees — the 10 content tracks, 172 individual issues mapped by quarter, the three Build It Yourself implementation series, the 12 annotated research papers, and the company case studies. Read this before you subscribe. If what you see here doesn’t match what you want to learn, this isn’t the newsletter for you. That’s fine — we’d rather you know now.
The 10 content tracks
Every issue belongs to one or two of ten tracks. These describe the primary lens through which the concept is examined.
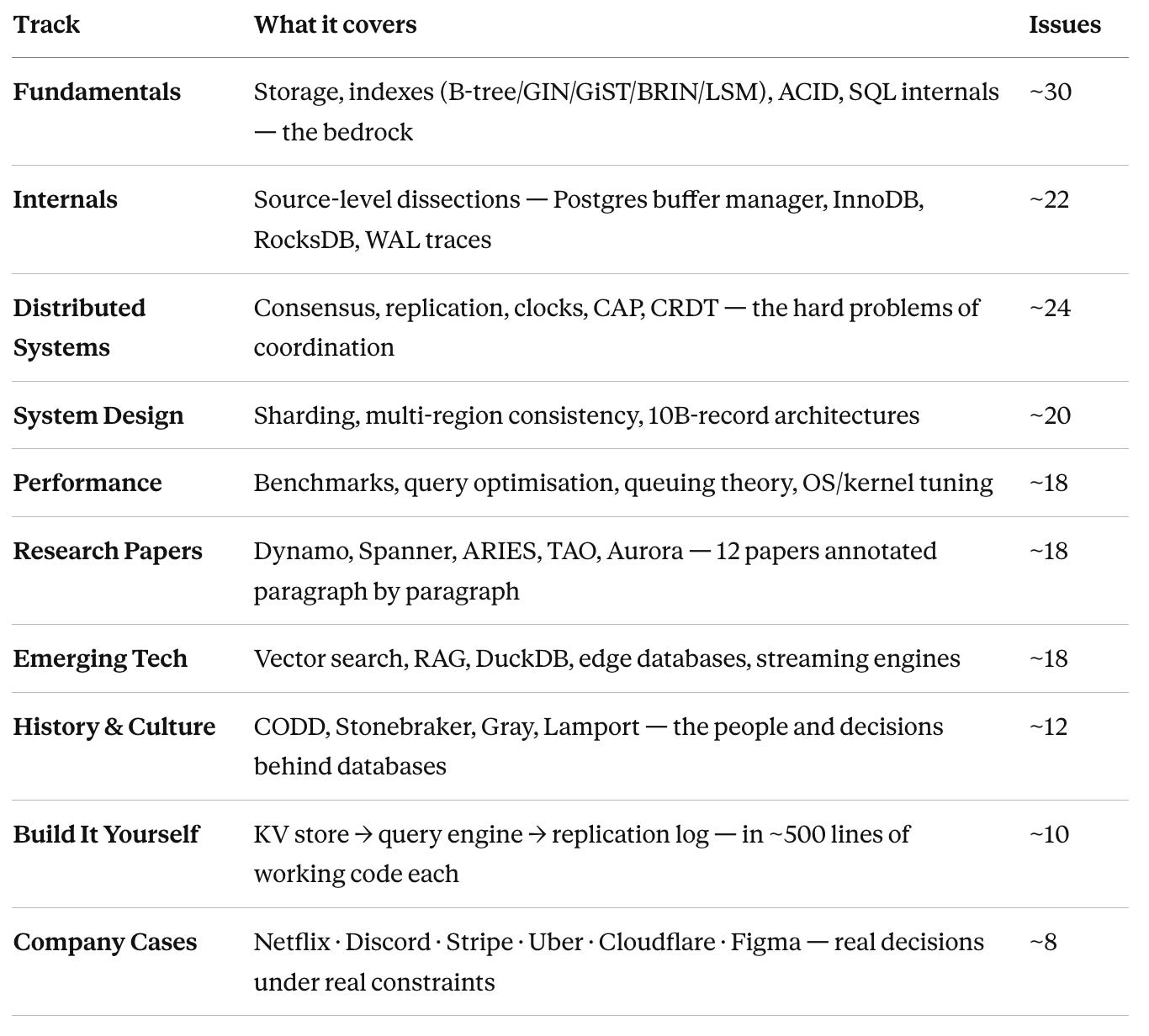
Total: 172 issues · 3 years · ~6,000 words each · 52 issues/year
Year 1 — Issues #001 to #056
Foundations: from storage physics to the full database taxonomy
Q1 (Issues #001–014): Why databases exist + Build It Yourself #1
#001 Data, storage & memory — first principles
#002 Disk geometry & the I/O stack — seek time, rotational latency, and what SSDs changed
#003 Files, block devices & the OS abstraction — where databases actually write
#004 Why flat files fail — the six problems that forced databases into existence
#005 IMS, CODASYL & the hierarchical model — what came before relational
#006 CODD’s relational model — the idea that changed everything
#007 Atomicity at the byte level — what “all or nothing” actually means in hardware
#008 Durability — what fsync guarantees, and what it doesn’t
#009 Isolation levels visualised — dirty reads, phantom reads, serialisable anomalies
#010 SQL and relational algebra — the formal foundation behind the syntax
#011 NULLs, three-valued logic & the SQL traps — why NULL is not zero or empty
#012 🔨 Build It Yourself #1 — Part 1: a key-value store: crash-safe writes & file pointers
#013 🔨 Build It Yourself #1 — Part 2: adding a hash index
#014 🔨 Build It Yourself #1 — Part 3: adding a write-ahead log & crash recovery
By the end of Q1: You understand why every ACID property exists at the hardware level, and you have a working key-value store that demonstrates all of it.
Q2 (Issues #015–029): Storage engines & indexing
#015 Pages, heaps & row storage anatomy — how Postgres lays out rows on disk
#016 TOAST & variable-length columns — how Postgres stores text and JSON that doesn’t fit
#017 Row vs columnar storage — when each wins and why the gap is enormous
#018 B-trees — the balanced tree on disk: why this structure, why this shape
#019 B+ trees — the leaf-linked difference that makes range scans fast
#020 Index-only scans, covering indexes & fill factor — the performance levers
#021 Index bloat, splits & the cost of maintenance — what indexes cost to keep
#022 ✨ GIN — generalised inverted indexes: full-text search & JSONB under the hood
#023 ✨ GiST & BRIN — the specialist indexes most engineers never encounter
#024 Hash indexes & bloom filters — when equality beats range lookup
#025 Bitmaps, skip lists & low-cardinality index structures
#026 LSM trees — why writes are cheap: the write path from memtable to SSTables
#027 SSTables, compaction & write amplification — the cost the write path defers
#028 LSM vs B-tree — the fundamental trade-off that shapes engine selection
#029 RocksDB internals — the LSM tree in production at Meta, Cassandra, and TiKV
By the end of Q2: You understand every major index structure — why it exists, how it works physically, and when to choose it.
Q3 (Issues #030–042): Query execution & concurrency
#030 Parse → plan → execute — the full lifecycle of a SQL query
#031 Cost-based optimisers & table statistics — how Postgres decides what to do
#032 Reading EXPLAIN like an expert — every node type, every cost field
#033 Nested loop, hash join & merge join — when each algorithm fires and why
#034 Join order & why it matters exponentially — the combinatorial explosion
#035 Parallel query execution — when Postgres uses multiple workers, when it doesn’t
#036 Two-phase locking in depth — how row-level locking actually works
#037 MVCC — why it’s the hardest thing in databases
#038 Vacuum, dead tuples & table bloat — the cost of MVCC deferred
#039 Optimistic concurrency & serialisable snapshot isolation in practice
#040 📄 Annotated paper: The ARIES algorithm — the paper that defined crash recovery
#041 WAL, redo logs & the crash recovery sequence — ARIES in Postgres
#042 InnoDB’s doublewrite buffer — why it exists and what it costs
By the end of Q3: You understand how a query goes from text to result, how concurrent transactions are isolated, and how databases recover from crashes.
Q4 (Issues #043–056): Database taxonomy + Build It Yourself #2
#043 NoSQL — what it genuinely gave up and what it genuinely gained
#044 Document stores & the BSON choice — why MongoDB stores data the way it does
#045 Key-value stores — simplicity as a deliberate design choice
#046 Column-family stores & the wide-row model — Cassandra’s data model explained
#047 Time-series databases & hypertable partitioning — TimescaleDB’s approach
#048 ClickHouse’s MergeTree — columnar storage for analytical workloads
#049 Graph databases — when property graphs beat recursive SQL
#050 The database selection framework — a decision tool for any workload
#051 OLTP vs OLAP — the architectural divide and why it matters
#052 Polyglot persistence — when one database genuinely isn’t enough
#053 Year 1 synthesis — your complete mental model, connected
#054 🔨 Build It Yourself #2 — Part 1: parsing SQL into an AST
#055 🔨 Build It Yourself #2 — Part 2: building a logical plan
#056 🔨 Build It Yourself #2 — Part 3: executing filter, projection & hash join
By the end of Year 1: You understand the full database landscape from first principles. You have built a key-value store and a working query engine. You can explain any database’s core behaviour from the bottom of the storage stack.
Year 2 — Issues #057 to #113
Internals & Scale: real engines, distributed systems, and performance mathematics
Q1 (Issues #057–069): Distributed foundations
#057 The 8 fallacies of distributed computing — each one a class of bugs
#058 Network partitions & partial failures — why distributed systems are fundamentally harder
#059 CAP theorem — what it actually claims, what it doesn’t, and how it’s misused
#060 Primary-replica replication anatomy — the standard topology dissected
#061 Statement vs row vs logical replication — the trade-offs in each format
#062 Replication lag, read-your-writes & monotonic reads — consistency guarantees
#063 Multi-master & leaderless topologies — when and why
#064 FLP impossibility — why consensus is provably hard in asynchronous systems
#065 📄 Annotated paper: Paxos Made Simple — Lamport’s algorithm, actually explained
#066 📄 Annotated paper: Raft — leader election with pictures
#067 Raft — log replication, safety guarantees, and membership changes
#068 etcd, CockroachDB & TiKV’s Raft implementations — theory in production code
#069 Why wall-clock time is dangerous in distributed systems
Q2 (Issues #070–084): Real engine dissections
#070 Lamport timestamps & vector clocks — establishing order without a shared clock
#071 📄 Annotated paper: Google TrueTime — atomic clocks, GPS, and Spanner’s clock API
#072 Hybrid logical clocks in CockroachDB — the practical compromise
#073 Postgres buffer manager & shared_buffers — the most important tuning knob
#074 Postgres query planner in depth — join reordering, partition pruning, statistics
#075 Postgres MVCC snapshots & visibility rules — which row version does a query see?
#076 Postgres extensions architecture — how PostGIS and pgvector plug into the engine
#077 MySQL InnoDB — clustered indexes, gap locks & next-key locks
#078 InnoDB binlog and the replication story
#079 ✨ Apache Arrow — the universal columnar memory format
#080 ✨ DuckDB — the in-process analytics revolution and why it’s architecturally novel
#081 Cassandra — consistent hashing ring, vnodes, quorum reads & anti-entropy
#082 📄 Annotated paper: Dynamo — Amazon’s highly available key-value store, paragraph by paragraph
#083 Redis — eviction policies, RDB vs AOF, cluster slot-based sharding
#084 Redis Streams as a persistent event log
Q3 (Issues #085–100): Sharding, cloud databases & OLAP at scale
#085 Sharding strategies — range, hash & directory: what each costs
#086 Hot keys, vnodes & resharding without downtime
#087 Vitess — MySQL sharding at YouTube scale
#088 CockroachDB — distributed SQL from the ground up
#089 📄 Annotated papers: Spanner & F1 — the two papers that changed distributed databases
#090 TiDB & YugabyteDB — the NewSQL generation
#091 ✨ Benchmark methodology — how to run honest performance comparisons
#092 ✨ Benchmarking SurrealDB, EdgeDB & Turso — reproducible, methodology-first
#093 📄 Annotated paper: Amazon Aurora — why “the log is the database”
#094 Neon — copy-on-write branching for Postgres
#095 PlanetScale — online schema changes at scale
#096 Serverless databases — economics, cold starts & architectural implications
#097 Snowflake — compute/storage separation dissected
#098 BigQuery’s Dremel engine — nested columnar storage
#099 ClickHouse vectorised execution internals
#100 The modern data stack — where the seams are
Q4 (Issues #101–113): Performance engineering + Build It Yourself #3
#101 Query optimisation — a systematic methodology beyond “add an index”
#102 Index design methodology — choosing the right index for the right query pattern
#103 Statistics staleness & its cascading effect on query plans
#104 Materialised views, lateral joins & window functions
#105 Schema design for write performance — normalisation and its limits
#106 Schema design for read performance — denormalisation and its costs
#107 PgBouncer modes, ProxySQL & the connection pool design space
#108 ✨ Queuing theory — Little’s Law, M/M/1 queues & database capacity planning mathematics
#109 The Linux page cache & how databases fight it
#110 io_uring — what it means for database I/O in practice
#111 NVMe topology, NUMA effects & huge pages
#112 OS & kernel tuning for database workloads — the full checklist
#113 🔨 Build It Yourself #3: a minimal replication log — primary, replica & failover
By the end of Year 2: You can dissect real database source code, design distributed architectures, size a connection pool using queuing mathematics, and explain every major cloud database’s architectural trade-offs.
Year 3 — Issues #114 to #172
Frontier, ultra-scale & synthesis: what’s next and how it all connects
Q1 (Issues #114–128): The emerging landscape
#114 Approximate nearest neighbour — the ANN problem and why exact search doesn’t scale
#115 HNSW — how hierarchical navigable small worlds work
#116 IVF, FAISS & product quantisation
#117 pgvector vs dedicated vector databases — an honest comparison
#118 ✨ RAG Part 1 — chunking strategies and their effect on recall quality
#119 ✨ RAG Part 2 — embedding pipeline design, staleness & update latency
#120 ✨ RAG Part 3 — hybrid search: BM25 + vector + re-ranking models
#121 ✨ RAG Part 4 — the full data architecture behind a production RAG system
#122 NL-to-SQL — where it works, where it fails, and why
#123 LLM-assisted query optimisation — research vs production reality
#124 Edge databases — SQLite’s architecture, Turso & libSQL
#125 CRDTs — offline-first sync without a coordination server
#126 ElectricSQL & local-first architecture
#127 Materialize & differential dataflow
#128 RisingWave — streaming SQL in production
Q2 (Issues #129–143): Research frontiers + company case studies
#129 Exactly-once semantics across stream and store
#130 📄 Annotated paper: The Case for Learned Index Structures — Kraska et al
#131 Learned cardinality estimation — replacing histograms with models
#132 Bao — learning to optimise queries from execution feedback
#133 🏢 Company case: Netflix — Cassandra, EVCache & the viewing history data model
#134 🏢 Company case: Discord — MongoDB → Cassandra → ScyllaDB, the full story
#135 🏢 Company case: Stripe — sharding Postgres when one instance isn’t enough
#136 🏢 Company case: Uber — Schemaless/Docstore for trip data at scale
#137 🏢 Company case: Cloudflare D1 — SQLite at the edge, globally
#138 🏢 Company case: Figma — scaling Postgres from one machine to many
#139 📄 Annotated paper: Napa — powering scalable data warehousing at Google
#140 CXL memory pooling & what it means for buffer management
#141 Persistent memory — what Optane taught the database industry
#142 TLA+ for distributed database protocol verification
#143 Jepsen — how Kyle Kingsbury breaks databases
Q3–Q4 (Issues #144–172): Ultra-scale design & 3-year synthesis
#144 Access pattern analysis for billion-row systems
#145 Partition key design — avoiding the hot key disaster
#146 Index topology for tables at extreme scale
#147 Geo-replication — designing for global latency
#148 Multi-region consistency patterns in production
#149 CRDTs in production — the failure modes nobody warns you about
#150 Event sourcing — the immutable log as a database
#151 Event sourcing pitfalls nobody warns you about
#152 CQRS — when and why to separate reads from writes
#153 Zero-downtime schema migrations at scale
#154 Database chaos engineering — breaking things safely
#155 Row-level security in depth
#156 GDPR right-to-erasure in an append-only system
#157 Audit logging without killing performance
#158 The people: Edgar F. CODD — the relational model and its reception
#159 The people: Michael Stonebraker — Ingres, Postgres, and 40 years of database design
#160 The people: Jim Gray — transactions, fault tolerance, and the 1998 Turing Award
#161 The people: Leslie Lamport — clocks, consensus, and distributed systems theory
#162 50 years of databases — the full economic and technical arc
#163 Where storage hardware is going — NVMe, CXL, photonic interconnects
#164 Post-SQL query models — what comes after the relational interface
#165 The AI query interface endgame — where NL-to-SQL leads
#166 The 3-year concept map — Part 1: Years 1 & 2 connected
#167 The 3-year concept map — Part 2: Year 3 and the full picture
#168 The complete trade-off matrix — every design decision, compiled
#169 The database selection framework — final version
#170 The performance engineering playbook — the full checklist
#171 The distributed systems decision guide
#172 Issue #172 — the final synthesis: 172 concepts, one mental model
By the end of Year 3: You can design systems for billions of records, understand and critique database research papers, explain the full 50-year history of database engineering, and synthesise every concept from all three years into a coherent, connected mental model.
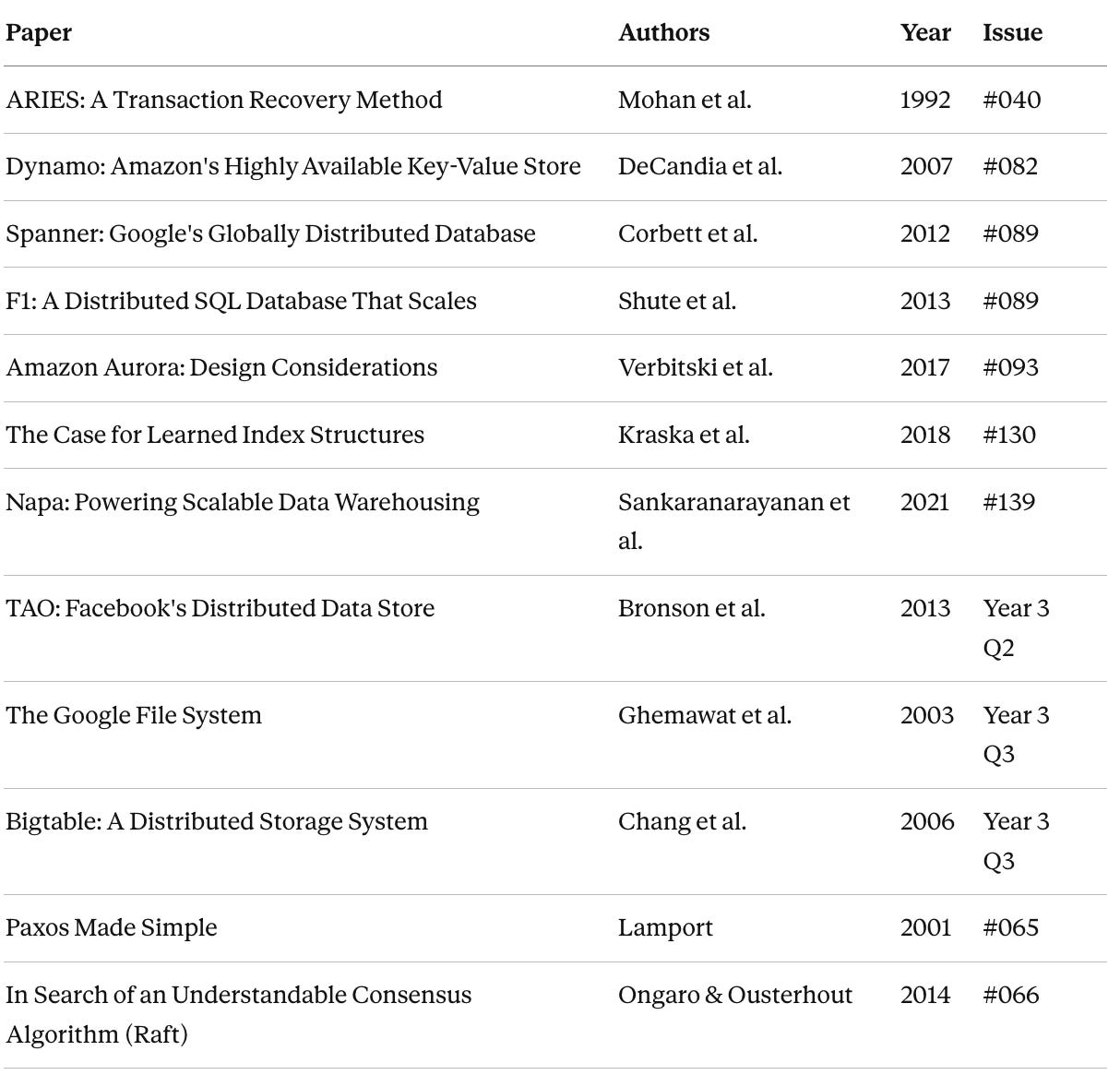
The 12 annotated research papers
Each paper gets a full dedicated issue: we read it together, paragraph by paragraph, translate the academic language into plain engineering, explain the context, and trace what the industry actually adopted.
How to use this guide
Bookmark this page. Each time a new issue arrives, return here to see how it connects to what came before and what comes next. The issue references in each week’s diagram panels all point to entries in this map.
The curriculum is designed so that every concept you encounter in Year 3 was seeded in Year 1 — this is the document that shows you where. The B-tree you learn in issue #019 reappears in issue #073 (Postgres buffer manager), and again in issue #146 (index topology at scale). Each time with more context, more depth, and more connection to the surrounding concepts.
One last thing
Databases are one of those rare engineering topics where genuine understanding compounds dramatically. The engineer who knows why a B-tree organises data the way it does doesn’t just understand B-trees — they immediately have better intuition about LSM trees, write amplification, columnar storage, and why certain Cassandra data models are catastrophically slow while others are fast.
Understanding is recursive in this domain. The more you have, the faster new concepts click into place.
That compounding is what the three-year structure is designed to produce. Not 172 isolated facts. One interconnected mental model, built one piece at a time, week by week, until databases stop being black boxes and start being something you genuinely understand.
Issue #001 ships this Sunday. See you then.
Subscribe — free tier always available. Issue #001: “Data, storage & memory — first principles.” Free for all subscribers.
© Bytes & B-trees · Substack · Weekly · bytesbrees.substack.com
Publish order: ① Promotional → ② Course Introduction → ③ This curriculum guide → Issue #001 (Sunday)